pythonでAmazonランキングをスクレイピングしてCSVで出力
2020/07/27
pythonで最近スクレイピングにハマっているらくがきです。
Amazonランキングっていちいち次ページを押さないとランキングが見れないので、めんどくさいんですよね
amazonのRSSでランキングを取ろうとしても、ランキングは20位くらいしかないし...AmazonのAPIも同様な感じ。
ってことで簡単にpythonでスクレイピングして、快適なAmazonライフをしてみたいと思います。
Amazonランキングをスクレイピング
Amazonのランキングをスクレイピングする前に予習することをオススメしています。
Beautiful SoupとPandasはインストールしないとエラーがでてしまい。出力できなくなります。
Python データ処理ライブラリ Pandas の導入とそのデータ型
以上を確認してもらってから説明に移ります。
まずは簡潔にすべてのコードになります。
import urllib.request, urllib.error
from bs4 import BeautifulSoup
import time
import datetime
import pandas as pd
uri = 'https://www.amazon.co.jp/'
category = 'digital-text'
browse_node_id = '2293143051'
info = []
def ama(url):
#各ページをhtml形式で抜き取る
html = urllib.request.urlopen(url)
soup = BeautifulSoup(html, 'lxml')
time.sleep(2)
return soup
def get_info(ele):
#辞書形式でランク、タイトル、URL、画像URL、価格を抜き取ります。
info = {
"rank": ele.find("span", class_="zg-badge-text").string.strip(),
"title": ele.find_all("div", class_="p13n-sc-truncate")[0].string.strip(),
"url": "https://www.amazon.co.jp" + ele.find_all("a", class_= "a-link-normal")[0].attrs["href"],
"img": ele.find_all("img")[0].attrs["src"],
"price": ele.find("span", class_="p13n-sc-price").string.strip()
}
return info
for n in range(1,3):
url = uri + 'gp/bestsellers/' + category + '/' + browse_node_id + '/' + '?pg=' + str(n)
soup = ama(url)
for ele in soup.find_all("li", class_="zg-item-immersion"):
info.append(get_info(ele))
today = datetime.datetime.now().strftime('%Y.%m.%d')
#pandasを使用してCSV形式で出力
df = pd.DataFrame(info)
df.to_csv('Amazon' + str(today) + '.csv',encoding='utf-8_sig')
ちなみに、上手くいくとこんな感じに出力できちゃいます。
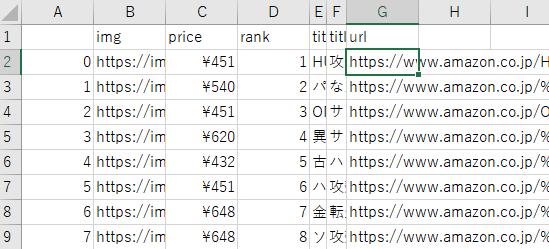
各コードについては順番に説明していきます。
ちなみに、自分の使用環境はwindows10になりますので、Macなどでは少し異なる部分もあります。
また今回のコードは、Amazonのkindleのベストセラーランキングをスクレイピングしたものなので、別のベストセラーやランキングをスクレイピングしたい場合は下の説明を参考にしてください。
AmazonURLの概念を理解して、情報を抜き取る
Amazonのベストセラーランキングは100位まであります。
以前は20づつで5ページ分ありましたが、サイトに変更がされて50づつの2ページ分になりましたね。
それに伴って少し変更を加えました。
URLを作成するプログラムをこのように表記しています。
uri = 'https://www.amazon.co.jp/'
category = 'digital-text'
browse_node_id = '2293143051'
for n in range(1,3):
url = uri + 'gp/bestsellers/' + category + '/' + browse_node_id + '/' + '?pg=' + str(n)
forで2回ループさせて、2ページ分のURLを作成しています。
ループしてURLを作成しているだけです。作成されたURL中身はこんな感じになります。
https://www.amazon.co.jp/gp/bestsellers/digital-text/2293143051/?pg=1
https://www.amazon.co.jp/gp/bestsellers/digital-text/2293143051/?pg=2
categoryやbrowse_node_idは見たいランキングによって異なってきますので、AmazonのURLを確認して変更してください。
例えばAmazonのKindle売れ筋ランキングを開き、URLを見るとcategoryとbrowse_node_idは下記赤文字のものになります。
https://www.amazon.co.jp/gp/bestsellers/digital-text/2275256051/ref=amb_link_15?pf_rd_m=AN1VRQENFRJN5&pf_rd_s=merchandised-search-1&pf_rd_r=78FZ2YTBE6B5CBJ05M25&pf_rd_r=78FZ2YTBE6B5CBJ05M25&pf_rd_t=101&pf_rd_p=58fa03ee-f8b6-4c5f-b2c0-e49b2a7ed5af&pf_rd_p=58fa03ee-f8b6-4c5f-b2c0-e49b2a7ed5af&pf_rd_i=2250738051
もし、別のランキングを取得したい場合は、categoryとbrowse_node_idを変更するだけで別のベストセラーのURLも取得することができます。
そして、これだけではサイトの情報を抜き取れていないので、BeautifulSoupを使用して情報をlxml形式で抜き取ります。その部分がこのコードになります。
繰り返し使うため、関数(def)でまとめています。
import urllib.request, urllib.error
from bs4 import BeautifulSoup
import time
def ama(url):
#各ページをhtml形式で抜き取る
html = urllib.request.urlopen(url)
soup = BeautifulSoup(html, 'lxml')
time.sleep(2)
return soup
各要素を抜き取る
各ページのlxml形式を抜き出せても、知りたいのはランキングだけです。
ランキングを抜き取るコードは以下の部分になります。
import urllib.request, urllib.error
from bs4 import BeautifulSoup
import time
import datetime
uri = 'https://www.amazon.co.jp/'
category = 'digital-text'
browse_node_id = '2293143051'
info = []
def ama(url):
#各ページをhtml形式で抜き取る
html = urllib.request.urlopen(url)
soup = BeautifulSoup(html, 'lxml')
time.sleep(2)
return soup
def get_info(ele):
#辞書形式でランク、タイトル、URL、画像URL、価格を抜き取ります。
info = {
"rank": ele.find("span", class_="zg-badge-text").string.strip(),
"title": ele.find_all("div", class_="p13n-sc-truncate")[0].string.strip(),
"url": "https://www.amazon.co.jp" + ele.find_all("a", class_= "a-link-normal")[0].attrs["href"],
"img": ele.find_all("img")[0].attrs["src"],
"price": ele.find("span", class_="p13n-sc-price").string.strip()
}
return info
for n in range(1,3):
url = uri + 'gp/bestsellers/' + category + '/' + browse_node_id + '/' + '?pg=' + str(n)
soup = ama(url)
for ele in soup.find_all("li", class_="zg-item-immersion"):
info.append(get_info(ele))
順番としては、下記のようになります。
- 各ページのURLをforでループで作成
- URLにアクセスしてlxml形式ですべて抜き取り
- forでさらにループしてfindallでランキングのlistを細かい要素を抜き取り
- 辞書型にして詰め込む
ここで抜き取ったデータはランク・タイトル・URL・画像URL・価格のデータを取得しています。
例えばランクの場合、classが"zg-badge-text"のstring(文字)をstrip()で空白・改行をなくして取得して、辞書型にするということになります。
これをただループして処理しているだけです。
classがどうやってわかるかと言うと、Googleのデベロッパーツールでわかったりします。
わからない人は初心者向け!Chromeの検証機能(デベロッパーツール)の使い方を確認してランキングはHTMLでどのように書かれているか確認してください。ある程度HTML・CSS知識を持っておくと理解はしやすくなります。
CSV出力
CSV出力のために抜き取ったデータをすべてリストに追加します。
そのため、空のリストを最初に用意しています。
リスト(info)に追加された情報は、pandasを使用してCSVで出力しています。
import datetime
import pandas as pd
info = []
for n in range(1,3):
url = uri + 'gp/bestsellers/' + category + '/' + browse_node_id + '/' + '?pg=' + str(n)
soup = ama(url)
for ele in soup.find_all("li", class_="zg-item-immersion"):
info.append(get_info(ele))
today = datetime.datetime.now().strftime('%Y.%m.%d')
#pandasを使用してCSV形式で出力
df = pd.DataFrame(info)
df.to_csv('Amazon' + str(today) + '.csv',encoding='utf-8_sig')
datetimeを使用していますが、これはファイルを日付毎に管理したかったのでいれました。
なくても問題はありません。
また、encoding='utf-8_sig'を使用しているのは、windowsだと文字化けが起こりやすくその文字化け解消のために入れています。
Macだとencoding='utf-8'でよかったと思います。
あと、HTMLの知識を上手く使うとDMでよくある画像が見れるメールを送ることもできます。
その辺は次回ぐらいに紹介しようと思います。
使用した書籍
[kattene]
{
"image": "https://ws-fe.amazon-adsystem.com/widgets/q?_encoding=UTF8&MarketPlace=JP&ASIN=487311778X&ServiceVersion=20070822&ID=AsinImage&WS=1&Format=_SL160_&tag=rakugaki020-22",
"title": "退屈なことはPythonにやらせよう ―ノンプログラマーにもできる自動化処理プログラミング",
"description": "Al Sweigart(著)",
"sites": [
{
"color": "orange",
"url": "https://www.amazon.co.jp/gp/product/487311778X/ref=as_li_tl?ie=UTF8&camp=247&creative=1211&creativeASIN=487311778X&linkCode=as2&tag=rakugaki020-22&linkId=a6744034396831d17819912d06715410",
"label": "Amazon",
"main": "true"
},
{
"color": "red",
"url": "https://hb.afl.rakuten.co.jp/hgc/17704933.97ca066a.17704934.54034512/?pc=https%3A%2F%2Fitem.rakuten.co.jp%2Fbook%2F14994167%2F&link_type=hybrid_url&ut=eyJwYWdlIjoiaXRlbSIsInR5cGUiOiJoeWJyaWRfdXJsIiwic2l6ZSI6IjI0MHgyNDAiLCJuYW0iOjEsIm5hbXAiOiJyaWdodCIsImNvbSI6MSwiY29tcCI6ImRvd24iLCJwcmljZSI6MSwiYm9yIjoxLCJjb2wiOjEsImJidG4iOjEsInByb2QiOjB9",
"label": "楽天"
}
]
}
[/kattene]
[kattene]
{
"image": "https://ws-fe.amazon-adsystem.com/widgets/q?_encoding=UTF8&MarketPlace=JP&ASIN=4798053635&ServiceVersion=20070822&ID=AsinImage&WS=1&Format=_SL160_&tag=rakugaki020-22",
"title": "現場ですぐに使える! Pythonプログラミング逆引き大全 313の極意",
"description": "金城俊哉(著)",
"sites": [
{
"color": "orange",
"url": "https://www.amazon.co.jp/gp/product/4798053635/ref=as_li_tl?ie=UTF8&camp=247&creative=1211&creativeASIN=4798053635&linkCode=as2&tag=rakugaki020-22&linkId=5557a3fba636faf9fc07fc8e920c485c",
"label": "Amazon",
"main": "true"
},
{
"color": "red",
"url": "https://hb.afl.rakuten.co.jp/hgc/17704933.97ca066a.17704934.54034512/?pc=https%3A%2F%2Fitem.rakuten.co.jp%2Fbook%2F15288396%2F&link_type=hybrid_url&ut=eyJwYWdlIjoiaXRlbSIsInR5cGUiOiJoeWJyaWRfdXJsIiwic2l6ZSI6IjI0MHgyNDAiLCJuYW0iOjEsIm5hbXAiOiJyaWdodCIsImNvbSI6MSwiY29tcCI6ImRvd24iLCJwcmljZSI6MSwiYm9yIjoxLCJjb2wiOjEsImJidG4iOjEsInByb2QiOjB9",
"label": "楽天"
}
]
}
[/kattene]
[kattene]
{
"image": "https://ws-fe.amazon-adsystem.com/widgets/q?_encoding=UTF8&MarketPlace=JP&ASIN=4297107384&ServiceVersion=20070822&ID=AsinImage&WS=1&Format=_SL160_&tag=rakugaki020-22",
"title": "Pythonクローリング&スクレイピング[増補改訂版] -データ収集・解析のための実践開発ガイド",
"description": "加藤 耕太(著)",
"sites": [
{
"color": "orange",
"url": "https://www.amazon.co.jp/gp/product/4297107384/ref=as_li_tl?ie=UTF8&camp=247&creative=1211&creativeASIN=4297107384&linkCode=as2&tag=rakugaki020-22&linkId=315bf8f2faba4acd20dc19b33c89b582",
"label": "Amazon",
"main": "true"
},
{
"color": "red",
"url": "https://hb.afl.rakuten.co.jp/hgc/17704933.97ca066a.17704934.54034512/?pc=https%3A%2F%2Fitem.rakuten.co.jp%2Fbook%2F15960670%2F&link_type=hybrid_url&ut=eyJwYWdlIjoiaXRlbSIsInR5cGUiOiJoeWJyaWRfdXJsIiwic2l6ZSI6IjI0MHgyNDAiLCJuYW0iOjEsIm5hbXAiOiJyaWdodCIsImNvbSI6MSwiY29tcCI6ImRvd24iLCJwcmljZSI6MSwiYm9yIjoxLCJjb2wiOjEsImJidG4iOjEsInByb2QiOjB9",
"label": "楽天"
}
]
}
[/kattene]